
A labor-market approach to model inference scheduling in soft-real-time systems
01 Jan 2023Now that I’ve elaborated how society is screwed due to generative AI, here’s a way to speed up the process via optimal resource utilization! I will show a reduction from model scaling/selection policy to the well-known labor economics problem, for which humanity has fantastic algorithms. But first, I have some thoughts about transferability between such problems.
Problem solving requires 3 things: processing, memory, and I/O. The first to execute operations, the second to store intermediate and finalized information, and the third to do something useful with it. This is a lesson I have learned in 5 very different classes across the years: cognitive psychology, circuits, algorithms, and biology. Yet each class introduced this like it was for the first time, like a teen who thinks their woes are unique. However, no amount of domain-specific jargon can hide the fact that nothing in this world is really that hard if you change your assumptions (unless it’s NP-hard). The challenge of course is finding that right set of assumptions, which requires some ingenuity from out-of-box thinking. Luckily, there’s a whole lot of people in this world with diverse interests, so we can pluck the best knowledge from “different” fields to solve our underlying problems.
I think this property is particularly beautiful under the algorithmic lens, where it has the name transferability. This is when knowledge and solutions of one problem readily apply to another, which offers deep insights into the primal problem’s structure. But like I mentioned, academic fields often get tunnel visioned into their own nomenclature and frameworks of thinking, so they tend to reinvent the wheel. But the problems in any one field are not unique, and are experienced by every other one in different languages. They are told using different stories and terms, but the heart of the problem is experienced by everyone; in my operating systems class, coordination of shared resources between distinct actors was introduced through the “Too much milk” problem, while in my macroeconomics class the same problem was introduced through the “Tragedy of the Commons” problem. So students are possibly in the best position to bring their fresh cross-discipline knowledge to break such boundaries between fields.
Systems may be the worst culprit of tunnel vision because of the immense constraint of practicality. Number theorists aren’t going to lose anything by theorizing some newfound property of integers. Very smart people fruitlessly dedicate their whole lives to proving the Collatz conjecture just for the fun of it. There is always hope, but never despair. But systems will kill people, or at the very least deliver an awkward amount of latency to load a web page, if they don’t deliver deadlines within constraints. It makes sense why systems programmers build their frameworks of thinking from the ground up: abstraction may bring slowness if improperly implemented, which lowers the utility of a solution. Visually, this shifts the curve of optimal solution points in the tradeoff space, the Pareto frontier, inwards. But Moore’s law has afforded us enough breathing room for abstraction to collect the best ideas from different disciples to build more robust systems.
A recent example of tunnel vision I recognized was in an OS research paper about machine learning model scheduling policy, called SuperServe. Assume you have a set of ML models characterized by two attributes: accuracy and latency per inference. If we’re operating in a soft-real-time system, then we want to maximize goodput, the number of queries that get handled before their deadline (latency service-level objectives (SLO) attainment), but we also always want to maximize the output’s accuracy, but we also want to minimize cost of inference. While the amount of time it takes for a single model inference is essentially deterministic (Clockwork 445), the incoming frequency of queries is constantly changing, and is characterized by short and frequent bursts like a stock-price graph. But switching models is a time-expensive operation because it involves reading RAM, or even disk space, to GPU memory. The task at hand is thus searching for the model that maximizes all 3 objectives while satisfying constraints. Optimizing this utility function under constraints is a hard task, and indeed we can prove it is by constructing an integer linear programming instance (Shepherd 793). The SuperServe paper proposed a solution to this problem that didn’t sit right with me.
 Figure 1. Microsoft Azure Functions incoming query frequency trace, showcasing both short burstiness and fluctuating mean.
Figure 1. Microsoft Azure Functions incoming query frequency trace, showcasing both short burstiness and fluctuating mean.
I mentioned switching models from GPU memory is a time-expensive operation, yet the optimal solution changes with the dynamic frequency of incoming queries. SLO requirements for DNN inference lies within 10-500ms (Shepherd 788), but swapping a model from RAM to GPU memory takes up to 750 ms for mere ResNet-152 (Model-Switching 4). Alas, research tends to lag behind state-of-the-art by a few years, not to mention that paper is from 2020. So to put that in perspective, ResNet-152 has 115.6 million parameters. Llama-3 8B has 8 BILLION parameters. You don’t even want to know how big Llama-3 70B is… This constraint necessitates a coarse-grained scheduling policy where the system must make conservative proactive decisions. Indeed, the authors recognize that “in a bid to offset the cost of loading models on the critical path of handling requests, inference serving systems rely on predictive scheduling policies that make coarse-grained estimations of future request arrival patterns.” But they go on to claim that “such policies are bound to be suboptimal owing to the difficulty of predicting the short bursts in request arrival rates coupled with their stringent SLO requirements” (SuperServe 3)…
Suboptimal to what exactly? They claim the reason is difficulty predicting short bursts in request arrival rates due to chaotic query frequency, but recall that coarse-grained policies do not attempt to handle short burstiness, but rather capitalize on easier-to-predict medium run trends. They also claim that stringent SLO requirements make model switching suboptimal, but what about applications where SLO requirements aren’t as stringent? The max SLO deadline this paper is basing off of is 50x more than the min (10-500ms); there are certainly a wide range of problems here. Maybe don’t use model switching in hard-real-time environments like self-driving cars, but why not in language models where I’d wait a little longer for a better response? With OS-scheduler deprioritization of idle models, our policy can prefetch multiple candidate models in RAM to avoid the more expensive disk-to-GPU load, making tail latency more managable (Model-Switching 4). In the space of course-grained policies, proactivity is indeed optimal following wisdom from financial markets, which I will get into.
The paper introduces their scheduling policy using a new mechanism called “Supernets,” a neural network architecture that trains many different models that share most of their weights. The result is a rich space of solution points that has a dense Pareto-frontier. The key innovation of supernet weight-sharing is that moving along the frontier does not require expensive model switching, but rather updating just a handful of numbers. This mechanism enables a “reactive, fine-grained scheduling policy that maximizes R1-R3 under unpredictable, bursty request rates.” The biggest benefit of a reactive policy is it has the straightforward integer programming setup from above. As this problem is NP-hard, they devised a clever greedy algorithm that capitalizes on the monotonic concavity of the Pareto frontier. This fine-grained solution clearly seems better than the old course-grained policies. There’s a logical error here: it evaluates a policy based on a mechanism it does not attempt to employ. You can only compare two policies when they use the same mechanisms.
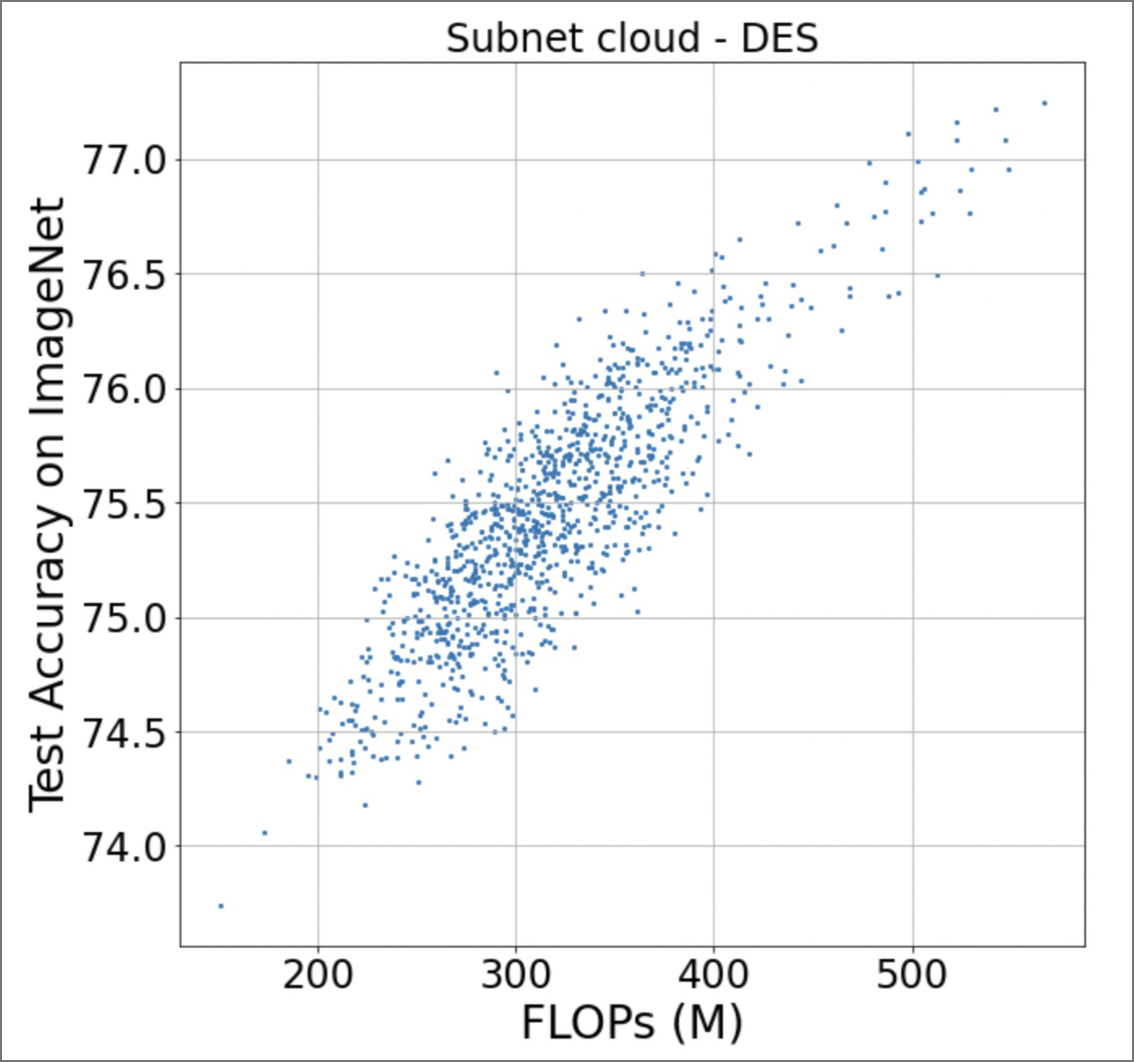
Figure 2. Rich tradeoff space for the Supernet architecture. The highest and most left points constitute the Pareto-frontier.
Why assume we’re using this niche technology and then fixing that problem instead? Ignoring the status quo does not make it go away. While being an optimal solution under the specialized supernet case, it abandons the heterogenous reality of today’s ML applications. Maybe one day neural architecture search (NAS) will constitute a significant share of deployed models, but today the technology is still NAScent. It’s like if microwave button technology was really bad and it took a long time to press buttons for the timer, people would naturally give up and nuke their food in Ez-on 30s increments. SuperServe feels like it’s saying “well if you go out and buy this nicer microwave, then our touchscreen allows you to button the timer 10x faster to enable fine-grained nuking!” Maybe next time I go microwave-shopping I’ll splurge for the touchscreen, but for now I have the one I have. What I need is for someone to come up with a better generalizable buttoning technique. Scheduling policies should live on the right hand side of the inference serving flow for sake of modularity, but the mechanism assumption interferes with the left hand side too. Thus, it can be marketed as an alternative setup, but not a general improvement.
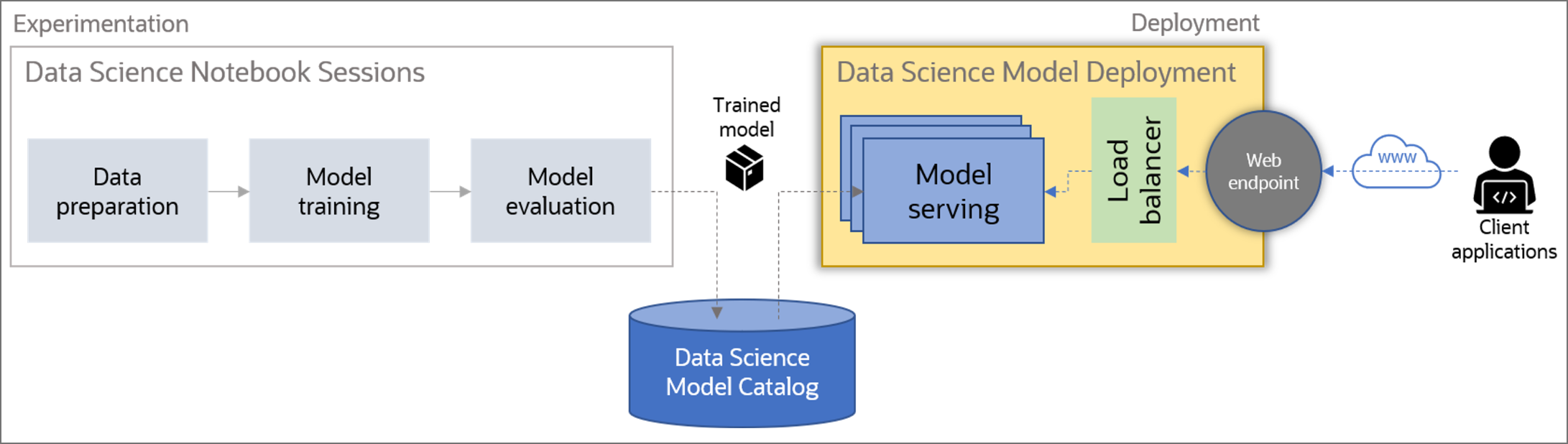 Figure 3. Model serving infrastructure flowchart, showcasing the dichotomy of responsibility between data science and systems components.
Figure 3. Model serving infrastructure flowchart, showcasing the dichotomy of responsibility between data science and systems components.
The key insight I’m trying to convey is that schedulers in uncertain environments indeed should not be reactive to bursty conditions in the first place. They should be proactive and extrapolate future trends because long-run query arrival rate is highly predictable. ML models would not struggle to predict such trends given a historical time series. Why am I making this assumption? Because in financial markets such as stocks, if you can’t do high frequency trading, then being reactive to bursty price changes is the easiest way to lose money, i.e. emotional human investors. But machine learning for trading is among the most successful applications of ML in history because of the predictability, even in medium and long term trading. Thus, I believe SuperServe only successfully optimizes the 3-dimensional tradeoff space because they relied on a niche mechanism that can brute-force react to bursty environments. While supernets may be the future of machine learning as a service (MLaaS), the large majority of applications today cannot rely on this instantaneous-switching luxury. But today’s solution is not to stick to static serving or naive proactivity as the status quo implies, but rather to borrow these ideas from fields like finance and refine our axiomatic base: proactivity maximizes expectation of utility in the face of uncertainty, even accounting for switching penalties.
Furthermore, coarse grained policies have an inherent advantage: the longer model switching takes, the more time we have to make our educated guess. I don’t mean decide what model to switch to as you’re in the middle of switching, I mean the resolution of query frequency you wish to capture is linearly proportional to the acceptable latency in decision making. If I want to capture sub-second bursts, then my scheduler better take less than a sub-second to react; if I want to predict 2 second trends, then my scheduler should take less than ~2 seconds leading up to prediction. Indeed, our SLO requirement relaxes with coarser granularity, allowing our policy itself a more accurate or cheaper solution in the Pareto frontier! By choosing to react to such small time slices, their policy is damned to the same chaos that plagues those small time slices. While fine grained policies operate under such restrictive constraints akin to a process scheduler, coarse grained policies relatively can take their sweet time (granted, concurrently a la Shepherd 792) and even use machine learning to decide which machine learning model to pick. How meta is that!
Another mentioned benefit is avoiding “complex scheduling policies that must reason about future request rates in a bid to avoid paying the latency of switching ML models dynamically under bursts” (SuperServe 3). As I mentioned, this proactive reasoning is a necessary evil for coarse-grained policies that still wish to dynamically navigate the tradeoff space. Finally, my insight is that this complexity doesn’t have to be implemented in the scheduler, but rather can use a black box algorithm to achieve the same benefits. This can lead to a generalizable best-of-both-worlds solution.
Let us pivot to a new problem. Below I’ve given an algorithmic definition of job searching, a universal experience:
Problem:
You are a laborer who can work one of many jobs, each characterized by salary, hours a week, and happiness. You want to work as few hours a week and be as happy as possible while still paying your bills on time. If you don’t pay your monthly bills on time, they grow with interest. If you anticipate the cost of living increasing soon, you may switch to a higher paying job at the cost of happiness or more hours of work. If you decide to switch jobs, you know how long it should take, but there’s some degree of uncertainty. The question is should you apply to a new job today?
EmploymentSearch(J, j, B, f)
Inputs:
- J: A list of possible job tuples, each of the form (s, h, t, p), with s salary per month, h happiness, t time per week, and p probability distribution of getting hired in some amount of time
- j: The job you’re currently working
- B: Time series where B[i] is the set of bill tuples, (c, d, p), for month i, where c is the cost, d is the deadline, and p(x) is the penalty when paid x units of time late.
- f: Your utility function where you want to maximize f(s, h, t)
Outputs:
- A job j’ ∈ J that you should start applying to today. If it’s the job you currently have, then it doesn’t take any time to switch.
This problem is resoundingly similar to ModelSched and has clear financial applications. Indeed, economists have studied this problem for decades to model what laborers should do to maximize their long-term utility. In this pursuit, laborers cannot be reactive to market changes due to the delay of job switching, akin to the coarse-granularity restraint of model switching. You need to make a proactive decision if you were to switch jobs, and you wouldn’t switch jobs because you had a higher bill just for one month.
Here is reduction from ModelSched to EmploymentSearch, such that you should switch models if and only if the output j’ ≠ j. Let our set of models be J by setting salary to throughput, happiness to accuracy, time per week to cost, and the probability distribution to the Dirac delta function (100% probability at one point) for the constant switching delay. Let the current model in GPU memory be j. Let the historical query frequency trace be B by setting cost to inference delay of j, the deadline to the query’s SLO deadline, and the penalty function to the type of service level objective (stepwise, linear, logarithmic). The utility function naturally translates to R1-R3 defined above. If j’ is a higher paying job, that means the cost of living (query frequency) is expected to increase, and you will need more throughput to deliver SLO requirements. If it is a lower paying job, then the query frequency is expected to decrease, and you can prioritize accuracy or lower cost based on your utility function. The notion of changing jobs naturally accounts for the 0 salary/throughput during the switching delay. To scale to many GPUs serving at once, you can model this as a family that collectively pays bills and may asynchronously switch jobs.
To address the fact that incoming bills have heterogeneous soft-deadlines, we will partition similar deadline queries into streams and pay them off independently, because “the aggregated arrival pattern across a group of request streams tends to be much more predictable” (Shepherd 790). Their key insight is that there is much lower variance across groups of streams compared to single incoming queries. This is a very good fundamental sign for the predictability of frequency for different classes of queries; it indicates there is an underlying trend, one that we can somehow incorporate into our policy.
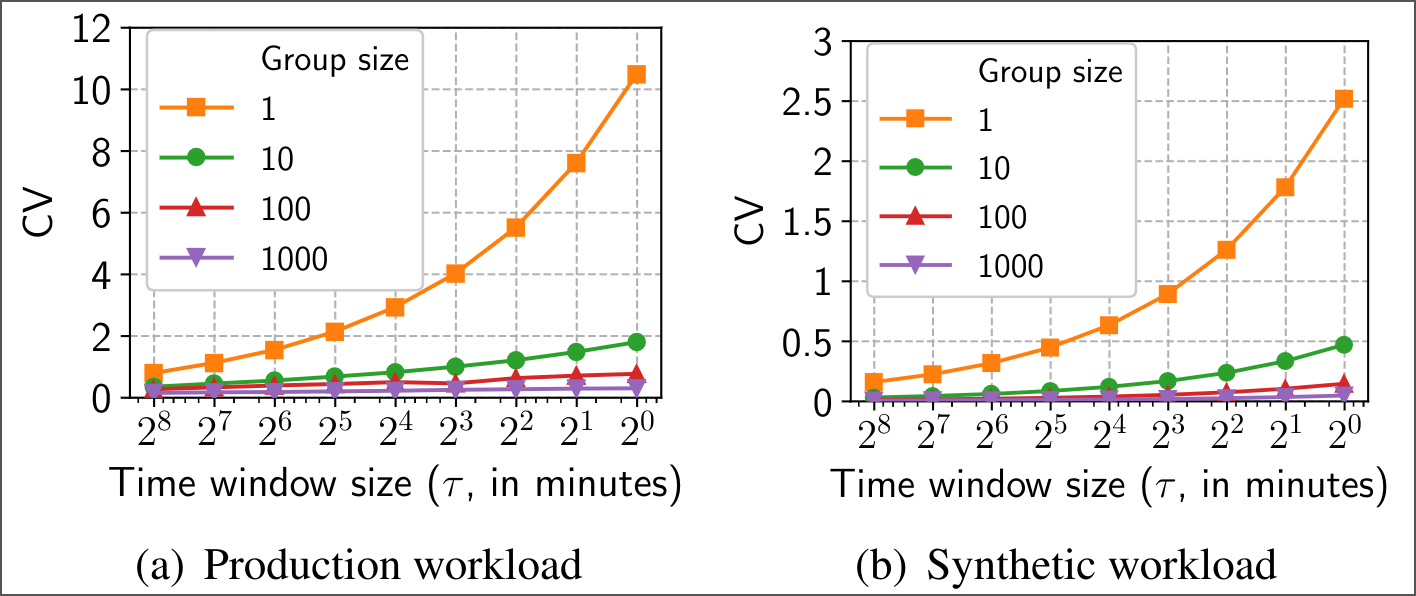 Figure 4. The coefficient of variance (CV) over the number of requests in each time window vs window size (τ, in minutes). The CV value increases dramatically as time window size decreases. Notice how real-world (production) conditions have 4x as much entropy as the simulated conditions, but entropy decreases superlinearly with group size.
Figure 4. The coefficient of variance (CV) over the number of requests in each time window vs window size (τ, in minutes). The CV value increases dramatically as time window size decreases. Notice how real-world (production) conditions have 4x as much entropy as the simulated conditions, but entropy decreases superlinearly with group size.
With exposition on this parallel problem, we can clearly identify that both problems are specialized cases of function extrapolation, where we predict the shape of a function to educate a decision. Now we can finally answer “what is the heart of proactive scheduling?” There are 4 shared characteristics that elucidate their fundamental properties.
- Sequential: The decision to switch is not a one-off event; it depends on past choices and affects future outcomes. You need to consider both the immediate and delayed consequences of actions.
- Uncertain: The conditions of the job market and personal financial needs can change unpredictably. You need to adapt to new data, continuously updating the policy as the environment evolves.
- Online: Deciding whether to switch to hold must happen in real time, without the luxury of waiting for all possible information to become available. As new information becomes available or as circumstances change, the policy must adapt its strategies.
- Feedback: Every time you make a decision, you can quickly evaluate its utility from positive or negative rewards. You can use this information to refine your future decisions.
These characteristics enable an agent in a partially-observable environment that learns the ideal policy incrementally, aka reinforcement learning. Indeed, this is a canonical setup that you would see in a textbook. Now here’s the beauty of reduction: instead of investigating how economists set up their reinforcement learning solutions, we will utterly ignore all of this and assume the finance people are doing something right. By treating job search like a black box, we gain all of the benefits from their algorithms with none of the work. Later, we can analyze what labor markets and scheduling have in common. Whether analysis researchers apply statistical methods, use successive derivation, or feature engineering is not our problem.
5 minutes of Google-Scholar-fu yielded these 3 papers solving the very similar career-planning problem with reinforcement learning. Just imagine what 10 minutes could do… [1] Predicts Dutch job market trends to maximize long term income for skilled workers. [2] Dynamically ranks career paths to maximize both short-term and long-term utility. [3] Predicts the best skill to learn to maximize utility, which is still largely mutually exclusive. My point is that economists have put the pins in place for us. Now we just need to fine-tune them to our query traces, and I predict the results will be very promising. This would enable us to use a solver while remaining proactive and coarse-grained. But maybe Google has been doing this behind the scenes all along and now I look like a chump. Anyway, I think my solution is particularly cool because it’s an example of ML for systems, which I don’t really know if that’s a thing yet. All I’ve seen so far is systems for ML. Pretty neat, right?