
Unit test LLM prompts through embeddings
01 Jan 2023LLMs are non-deterministic by nature, which means our prompts can’t be traditionally unit-tested. Instead, assert that the similarity between the model’s output and your reference output is above your defined threshold. We first calculate the vector representation of both pieces of data, and then take either the Euclidian distance, cosine, or dot product of the vectors.
Why are LLMs non-deterministic in the first place?
You’ve probably been explained a thousand times that LLMs “calculate the probability of the next word in a sequence.” So given an input sequence, an LLM will output a raw “score” for all possible words in its vocabulary, called the logits. These scores are put through the softmax function to generate a probability density function that looks like this:
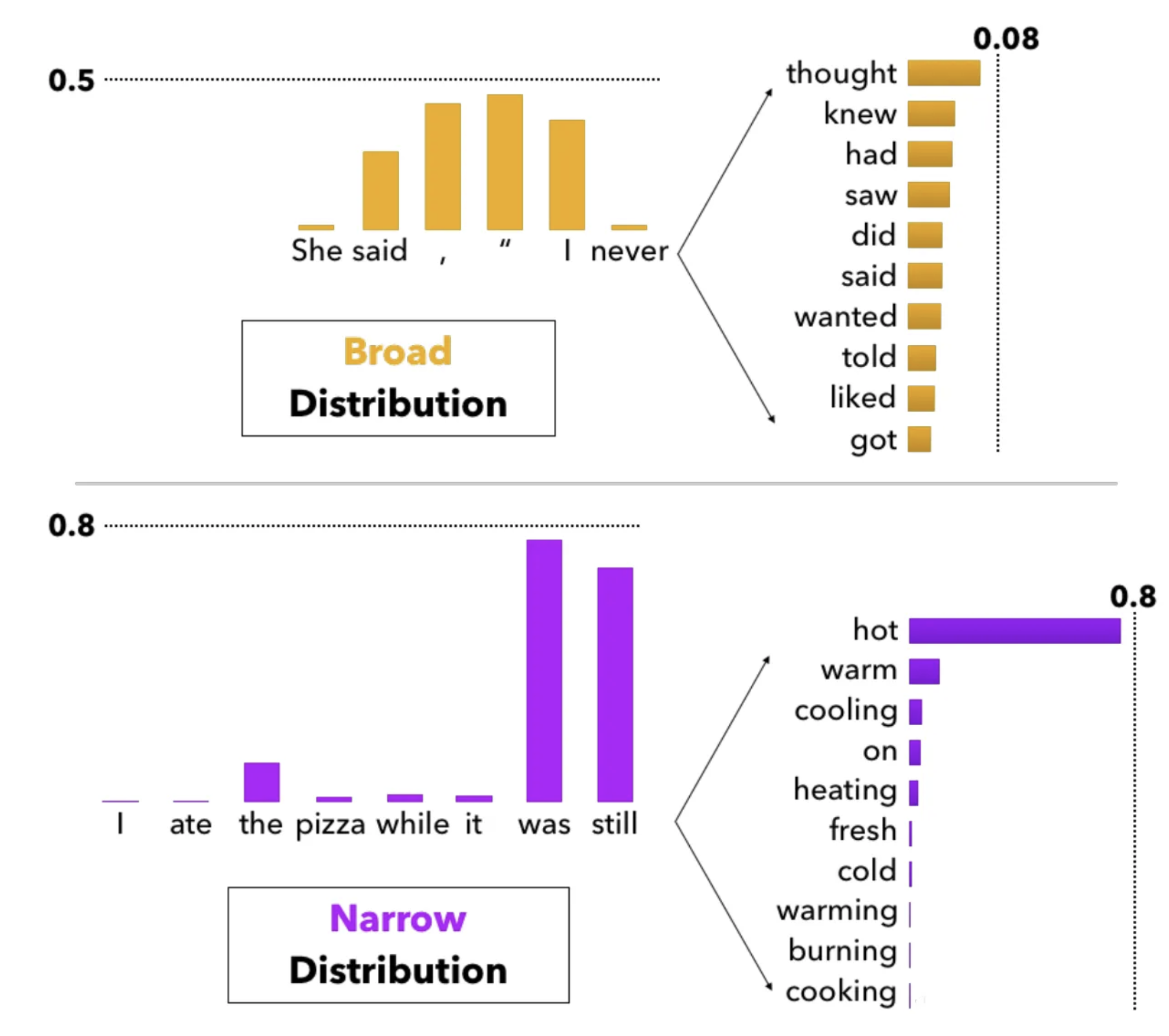
However, picking the max logit at all times is undesirable for language models, because it avoids exploring creative pathways of text generation. That’s why the sampling method respects the probability distribution and intentionally introduces randomness (like with np.random.choice). But even still, there is no way to control the degree of randomness, which limits the versatility of the model. Think medical diagnosis vs advertisement.
Thus, a hyperparameter temperature, or T is introduced. The logits are divided by T before softmax. An important node is that softmax is an exponential function, meaning it’s sensitive to small changes in its input. So as T approaches…
- 0, the exponential function becomes extremely sensitive to the highest logit. Even small differences in logits get magnified exponentially, making the highest logit overwhelmingly more probable than others. This output should deterministic.
- 1, no changes are made, and the models outputs are directly converted to probabilities.
- infinity, the differences between the logits become negligible after division, making all outcomes equally likely. This output should be uniform.
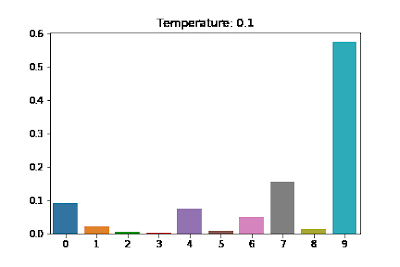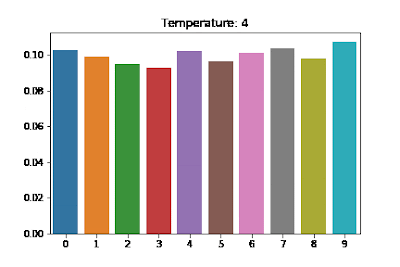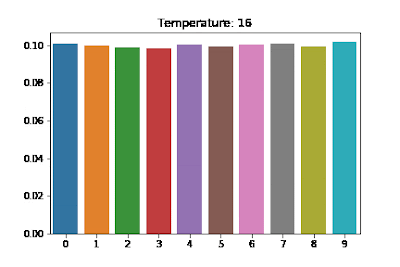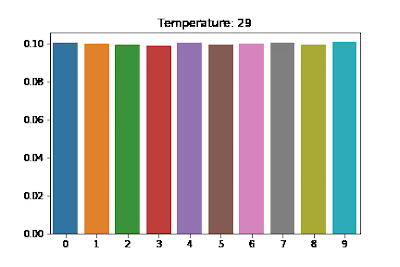
The default value is 1 for OpenAI’s API and ChatGPT products. If we set T to 0 (Note: to avoid divide by 0, T is replaced by some tiny value), then we should have coherent, deterministic output that is friendly to unit-tests. But especially when the LLM takes a user-facing role, a higher temperature is desirable for more creative and interesting answers. So how have people been testing their prompts, and a step further down the line, functions that rely on LLM output?
Well first, a funny answer. This Medium article gave the hilarious advice of use function calling, or just give up and make your program act as “routers, moving outputs from place to place.” It gives flowery language like “stay inside soft systems” where all text is equal and our test suite can’t annoyingly ValueError if we don’t actually test the thing. Our options are restrict the output to our own functions (which is very useful in internal code), or bow down to the pseudorandom gods.
So let’s investigate a different approach, albeit with a tradeoff. How about sacrifice creativity in our output and set temperature to 0.0?
Wait, WHY IS TEMPERATURE=0 STILL NON-DETERMINISTIC!?!
If you’ve tested this for yourself, you may have come to the horrible realization that deterministic output is impossible with the architecture we have today. Researchers disagree on why quite a bit, and because of the closed source nature of the models, we still don’t know for sure. We’ve essentially narrowed it down to two sources:
- Floating point rounding errors accumulate with parallelized GPU operations: small rounding errors in the forward pass can sometimes lead to a singular token being different, which has significant impacts due to the nature of transformers. If the forward pass was serially executed, then the rounding error would be reproduced every time. Except, since these operations are parallelized on the GPU, the operations happen out of order as long as they are combined synchronously, meaning small rounding errors are not reproduced deterministically. Source.
- Mixture of Experts architecture: It is public knowledge that GPT-4 is not a singular transformer, but a MoE (mixture of “experts”) that make a collective decision. Each “expert” is a sub-model trained to be proficient in a specific task, but there can be overlap between them to increase flexibility. There’s a separate sub-model called the “gating network” that analyzes the input and decides which expert(s) should be consulted, and the output is a weighted sum of the experts. When serially fed inputs, the same “experts” would be consulted to form the same output. But with so many tokens to process from different sequences, the gating network buffers tokens into groups of a fixed size. Thus, within each group, tokens fight each other for available spots in the expert buffers due to compute restrictions. You don’t know ahead of time what sequences will be jumbled together, meaning the same experts will not be consulted every time, meaning “some input sequences may affect the final prediction for other inputs.” Source.
This means we have to tweak our testing strategy to overcome this pestering non-determinism. First, let’s introduce a new task to help us get there.
Test similarity, not exact match
Supervised similarity measure is a supervised learning problem where an autoencoder model (combination of encoder and decoder where the model must learn to compress the input) is trained on a massive corpus of data where the features are both the input and label. The output of the encoder is a dense, high dimensional vector that captures the semantic meaning of the data, which we call the embedding. The embedding of two different datums can be compared like you would normally compare two vectors in linear algebra land: distance, cosine, and dot product. For more information, see this Google developer article.
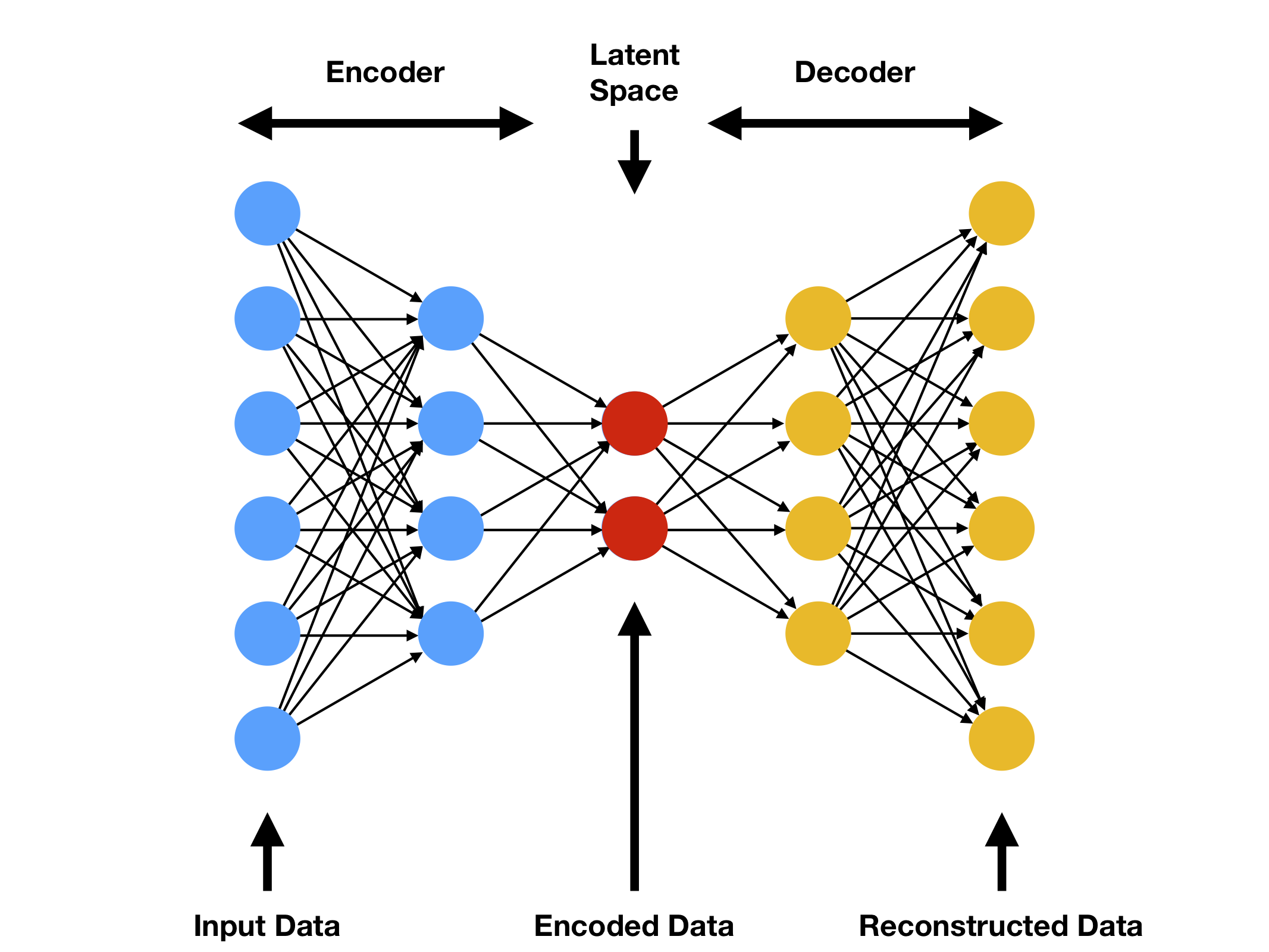
So a smarter way to unit test prompts is to generate and compare these two embeddings on demand. This should ideally be done locally and with a fast, lean model to keep pace with the rest of the test suite.
So what have developers actually been doing?
Well it seems like they have settled on two testing mechanisms:
- Do it yourself: Follow advice from an article like this , pick a reference answer, and test it with some metric. The benefit is it makes sure you properly understand the metrics you’re using, while fitting well into your existing test infrastructure. The downside is there can be quite a lot of boilerplate code involved if you pick a more sophisticated solution than
spaCy. promptfoo: This is an excellent solution! For a standard xxxGPT program, I would highly recommend this one for the following reasons:- It has a comprehensive set of assertion types that includes semantic similarity through embeddings! The most useful ones are the cosine similarity and sentiment classifier, using either OpenAI or local models.
- By using an external configuration file, it remains language-agnostic.
- It includes an intuitive and beautiful UI with automatic graph generation.
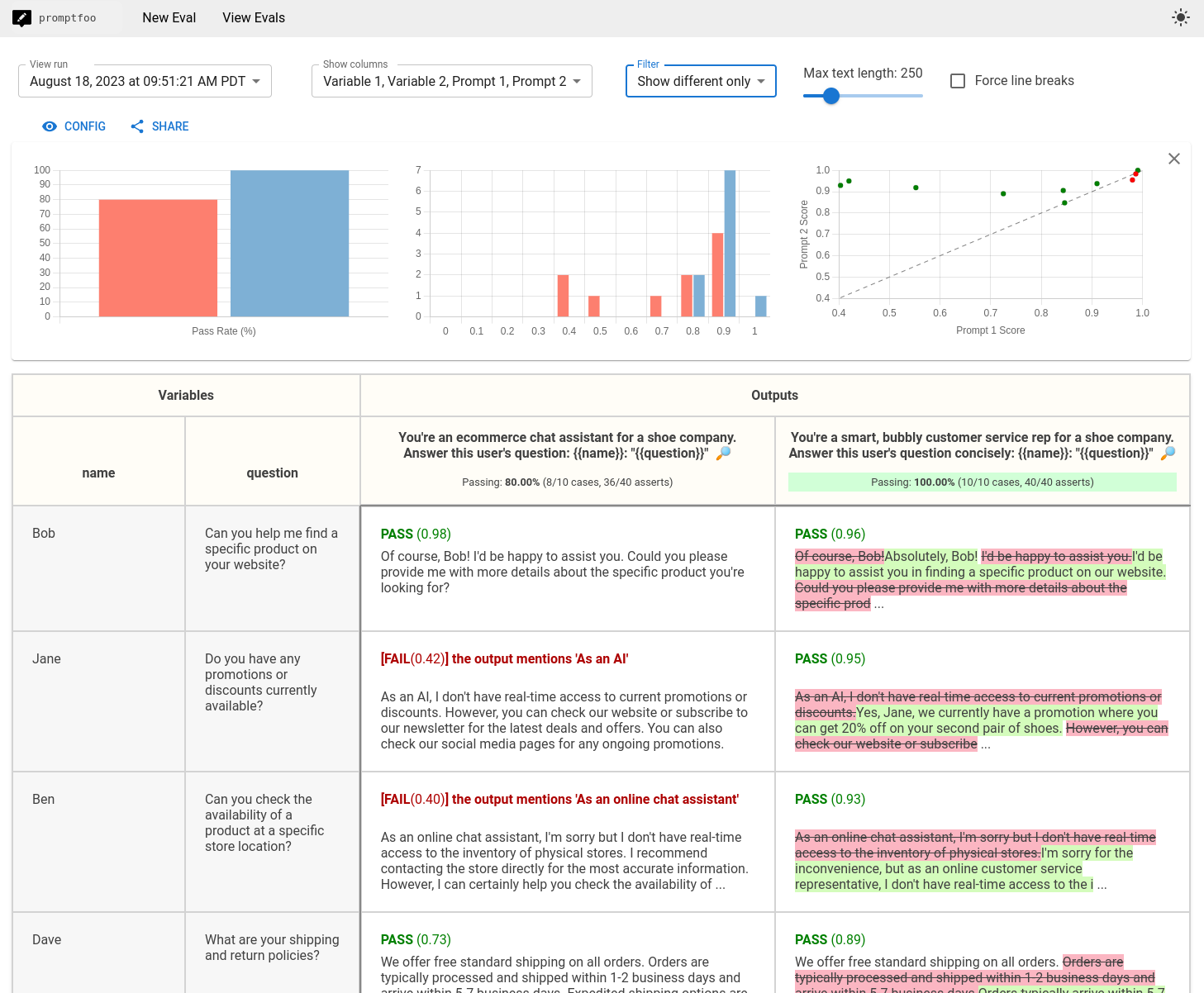
But alas, I am still writing, meaning my nitpicky brain has found something to complain about. I have two problems with promptfoo.
- It does not fit into existing Python testing infrastructures at all. It includes a library function
evaluateto integrate into your code, but only for JavaScript. yucky. - It involves learning a new complex system that may be too feature-complete for your needs. Indeed, it creates its own ecosystem to solve this testing problem.
Introducing: determinist
- It’s dead simple. It’s a single Python file consisting of a handful of functions, and ships with a very small embedding model ready to use.
- Fits seamlessly within
pytestandunittest. All you have to do is pass in your acceptance threshold, and iterate on it a few times until you deem it acceptable. No additional learning is required.
Why shouldn’t you use it?
- If the LLM’s output is the main function of your program, then you need a platform to maintain extremely high quality. For this purpose,
promptfoois excellent.
Note: THIS SOFTWARE DOES NOT EXIST YET. This is simply the rationale and design I’m laying for myself ahead of time.