
Generate personalized documentation for users and developers of OSS
02 Jan 2023Learning new software is hard. Even though we’re in a time where writing software is easier than ever due to ChatGPT and the likes, finding information that’s right for your comfort level and exposure to the project hasn’t become much easier. There’s an abundance of online resources to learn how to use open source software (OSS), but we need a better way to sift through the mountains than a Google search or potentially out-of-date ChatGPT response. Thus, the goal of chatter is to reduce the barrier of entry for newcomers to become users and users to become contributors through personalized documentation, while still being fully free. This is done through a RAG system that maximizes choices for maintainers and users. It defines a pipeline to get information into the database and for users to generate useful responses from it.
How do people learn about OSS today?
The knowledge of OSS is usually spread across many online sources, but follows popular conventions:
- README.md: The landing page for newcomers, and often the only source of usage, installation, and contribution documentation.
- Online forums: Allows users and contributors to discuss anything about the software: feature requests, bug reports, likes and dislikes, comparisons to alternatives, algorithmic improvements, etc.
- Messaging server (Discord): Allows users and contributors to informally communicate in real time about the same as above.
- Issue tracker: Allows users to discuss problems so other users can replicate them and contributors can investigate them.
- Pull request tracker: Allows contributors to request changes to the codebase to fix an issue, and for maintainers to view and test pending requests.
- Man pages: Source of truth for usage instructions.
- CHANGELOG.md: An up-to-date history of high-level, semantic changes made to the project.
- Commit history: An up-to-date history of low-level, code-wise changes.
Google’s search engine usually does a stellar job routing you to the right place (even better than Reddit’s own search), but there is a fundamental problem. This static information is not personal and creates overhead to find and to understand it. Even if you try very hard to consolidate them together into a website, this is a manual process that needs constant updating. Furthermore, a lot of work is expended to tailor the information to people of all levels of proficiency and background, which is something smaller teams simply don’t have the resources for. We need an improved, democratized information dissemination approach.
Introducing: chatter
Our task is defined as follows: given a query from a user, contributor, or maintainer, respond with factual and current information that answers the query encourages the person to become more involved with the project. Be ready to support your answer with the proper documents.
We will solve this with retrival-augmented generation. Here’s an outline of the 5 problems we need to solve:
- The information is spread across disparate online sources. We need to consolidate them together into one database.
- We don’t know what type of information the user is expecting. Decide the proficiency level of the question, and thus which sources of information to prefer.
- The query should not return exact matches, but rather semantically similar matches. Store the information in such a way that semantic information is readily comparable.
- The documents procured in the query should be turned into a natural language response without hallucinations. We need a language model, a way to give it the documents from (3), and a pragmatic prompt.
- The database from (1) and the language model from (5) should be accessible by any user for free or nearly free. Maintainers need a low-cost way to host the database, and users need the same for the language model.
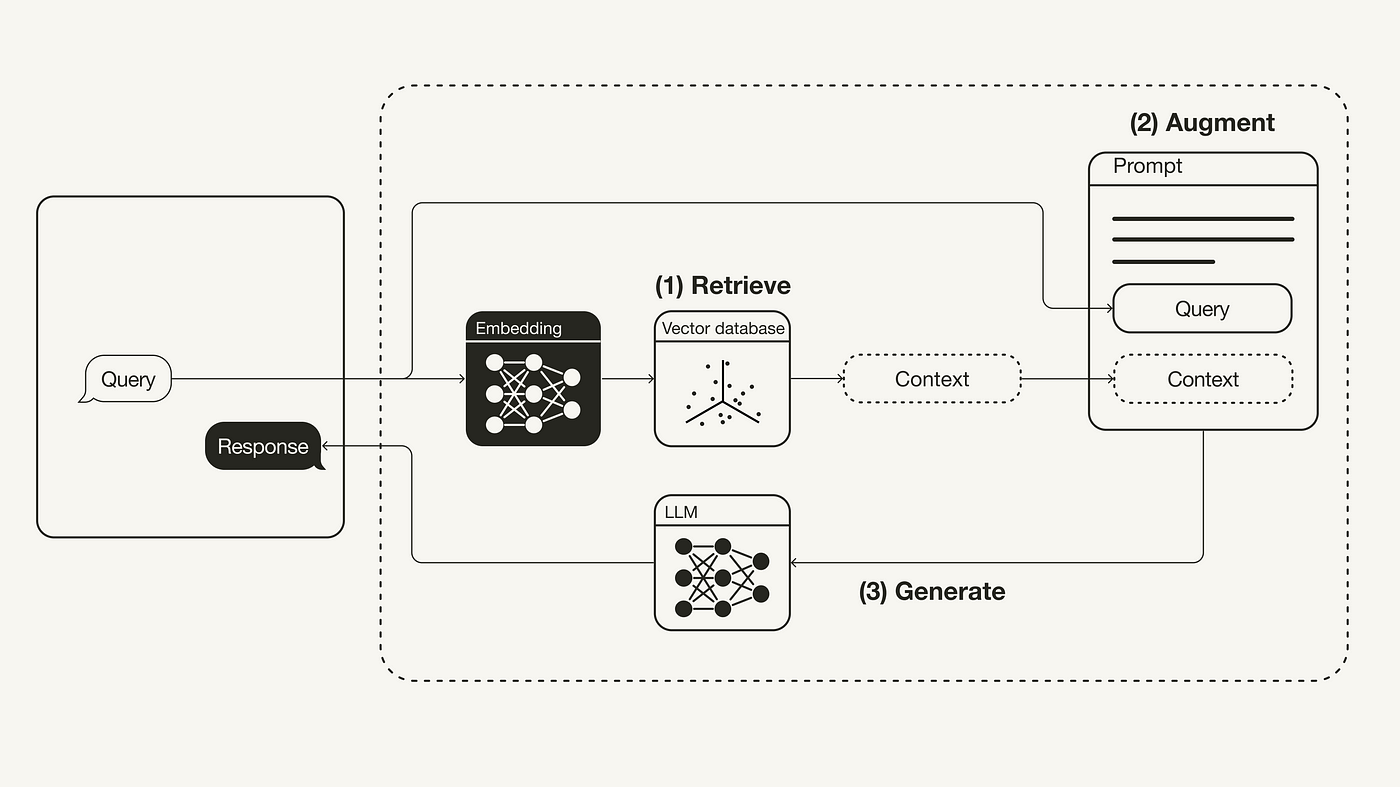
Consolidating information
Thankfully, we have well-defined conventions for where our information lives. It is feasible to scrape together these sources from local files and the internet at regular intervals. They should be stored in either a database file that lives in the repo, or hosted online by the maintainers while being kept safe from attacks. Note: the lack of conventions in proprietary software is the same reason a system like chatter will not work; the sources of information are product-specific and usually not scrapable.
Deciding proficiency level
We need a multi-class categorization model to group queries into proficiency “bins”. This will provide a weighted ranking of what information sources from above to prefer when answering the users query. For example, the query “how to install on M1 mac” will prefer online forums, messaging server, and README.md over other results. And the query “critical code segments that need optimization” will prefer issue tracker, pull request tracker, and online forums.
Semantic search
Search algorithms have gotten quite sophisticated since the days of exact match, for example by checking synonyms and sub-phrases. But the state-of-the-art is to convert text to dense, high dimensional vectors that captures the semantic meaning of the data, which we call the embedding. We can compare two embeddings semantically like we would compare two vectors in linear algebra land: distance, cosine, and dot product. It will be the maintainers job to convert documents to embeddings. We also must ensure the embedding model performs well with widely different types of documents, from formal documentation to informal Reddit posts.
Natural language generation
Now that the user has a way to query relevant documents with semantic search, these should be the context to a language model that generates a more useful response. This is the user interface to the whole system.
Addressing resource constraints
The principle problem is the scarcity of resources for the database and neural networks:
- Query binning: Ideally, we would have a dataset of software questions labeled with complexity so we can train an edge-friendly, low-parameter model. What is more feasible is to preprocess the queries using an LLM, which cleans the input and can simultaneously return a category.
- Text embedding: The state of the art of text embedding is to use transformers, but there are many free options beyond OpenAI. Either way, the same model must be used at all times, or at least different models that have the same embedding space.
- Vector database: This should be stored as a file with Git Large File Storage (GLFS). A fascinating option is to use sqlite-vss. If hosted with a cloud platform, another option is pgvector for Postgres. I would recommend staying away from flashy vector database startups for the same reason people cook at home.
- Generative language model: The user should have one locally setup, and the project maintainers provides the prompt tailored to their project structure. Two local options are TinyBERT or Llama 2 7B, or alternatively using the GPT API. The biggest benefit of this RAG system is that there is no expensive fine-tuning required, and the same language model can be shared across all projects the user wishes to query, given that the project maintains a vector database. This also avoids a potentially significant financial burden on the maintainers.
Who’s paying for all of this?
As stated above, the database and models used should be free and able to be run locally. The storage of the database should conveniently come from GLFS, the compute for the embedding generation should come from the maintainers, and the compute for natural language generation should come from the user.
How do you keep it up to date?
Provide a GitHub action for every information source, and let the maintainers decide the frequency of update. For local files and information (trackers, README.md, CHANGELOG.md), they can update upon every relevant change or commit. For large repositories of information like Stack Overflow posts, they can update every major pull request or release. Alternatively, they can update upon every release, because since the database file is version controlled, the user can query the appropriate file for their installed version.
Features
Now that we’ve defined the information pipeline, how should a system like this benefit OSS and its users?
- Interactive tutorials: Provide commands or real-time code examples tailored to the user. This can help users understand how to use different features of the software effectively, as well as automatically suggest fixes or workarounds for common issues.
- Automated code review: By analyzing the codebase and changelogs, the system could automatically review new code submissions, comparing them against past changes and best practices documented in forums or issue discussions.
- Documentation generation: Utilizing changelogs and forum discussions, the system could automatically update README.md to reflect recent changes or add FAQ sections based on common queries in the forums.
- Issue generation: The system could analyze the forum discussions to identify common or recurring problems. Using this data, it could preemptively update the issue tracker or suggest best practices to avoid these issues.
- Version-Specific Documentation: If the maintainers update the database every release, then it can documentation that is tailored to specific versions of the software. Users can specify their version to access the most relevant information, ensuring they’re not following outdated or inapplicable instructions.
- Coding copilot: A limitation of GitHub Copilot and ChatGPT is that they do not know the codebase and documentation of your project, because that requires retrieval-assistance. But while coding, the system could suggest relevant portions of documentation, similar past issues, or code snippets that relate to the task at hand.